

Optimizarea costului și utilizării clusterului Databricks fără tabele de sistem
În majoritatea mediilor enterprise Databricks (cum ar fi în MSC sau ecosisteme mari de analiză), tabelele de sistem precum system.jobrunlogs sau system.cluster_events pot fi restricționate sau dezactivate din cauza politicilor de securitate sau guvernanță.
Cu toate acestea, monitorizarea utilizării clusterului și a costurilor este crucială pentru:
- Înțelegerea cât de eficient joburile utilizează resursele de calcul
- Identificarea clusterelor inactive sau scurgeri de costuri
- Prognozarea bugetului de infrastructură
- Construirea dashboard-urilor personalizate de costuri
Acest blog demonstrează o abordare pas cu pas pentru calcularea utilizării clusterului și a costurilor utilizând doar API-urile REST Databricks — fără a necesita tabele de sistem.
Cazul de utilizare al proiectului
În platforma de date MSC, rulăm multiple clustere Databricks în medii de dezvoltare, testare și producție. \n Am avut trei provocări majore:
- Fără acces la tabelele de sistem (restricționate de politicile de administrare)
- Clustere efemere pentru joburi create dinamic de ADF sau pipeline-uri de orchestrare
- Fără vizualizare directă a modului în care utilizarea clusterului se transpune în cost
Prin urmare, am construit un analizor de utilizare ușor care:
- Extrage date din API-urile REST Databricks
- Calculează timpul de rulare al jobului vs timpul de rulare al clusterului
- Estimează costul utilizând ratele DBU și VM
- Generează un DataFrame ușor de consumat
Problema și abordarea
Provocarea identificată
Echipele trebuie adesea să știe:
- Care clustere sunt inactive (rulează cu activitate redusă de joburi)?
- Care este procentul de utilizare (timpul de rulare al jobului vs timpul de funcționare al clusterului)?
- Cât costă fiecare cluster (DBU + VM)?
Când tabelele de sistem Unity Catalog (de ex., system.jobrunlogs) nu sunt disponibile, abordarea implicită bazată pe SQL eșuează. API-ul REST devine alternativa de încredere.
Abordarea la nivel înalt utilizată în notebook
- Listează clusterele prin /api/2.0/clusters/list.
- Estimează timpul de funcționare al clusterului utilizând timestamp-urile din JSON-ul clusterului (câmpurile created/start/terminated). (Aceasta este o alternativă pragmatică când /clusters/events nu este disponibil.)
- Obține rulările recente de joburi utilizând /api/2.1/jobs/runs/list cu filtre de timp (sau limită).
- Potrivește rulările de joburi cu clusterele utilizând clusterinstance.clusterid (sau alte metadate de cluster).
- Calculează utilizarea: utilizare % = totaljobruntime / totalclusteruptime.
- Estimează costul utilizând o formulă simplă: cost = runninghours × (DBU/hr × DBU asumat) + runninghours × noduri × VM $/hr.
Acest notebook utilizează în mod intenționat interogări delimitate (ultimele N rulări, fereastră de timp) pentru a rula rapid.
\ 1. Configurare și setări
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Această secțiune inițializează:
- URL-ul workspace-ului și token pentru autentificare
- Intervalul de timp pentru care doriți să analizați utilizarea
- Presupuneri de costuri:
- Rata DBU ($/oră per DBU)
- Costul nodului VM
- Consumul aproximativ DBU
În configurații enterprise, aceste rate pot fi preluate dinamic prin API-urile FinOps sau de facturare.
-
Funcție wrapper API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Această funcție ajutătoare standardizează toate apelurile GET către REST API. \n Ea:
-
Construiește URL-ul complet al endpoint-ului
-
Gestionează 404 cu grație (important când clusterele sau rulările au expirat)
-
Returnează JSON parsat
De ce contează: Această funcție asigură comunicare curată cu API fără a întrerupe fluxul notebook-ului dacă lipsesc date despre cluster.
\
-
Listează toate clusterele active
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ Aceasta recuperează toate clusterele disponibile în workspace-ul dvs. \n Este echivalent cu vizualizarea programatică a filei "Compute". \n Răspunsul conține:
-
ID-uri de cluster
-
Nume
-
Numărul de noduri
-
Informații despre creator
-
Timpii de creare și terminare
Caz de utilizare: Ajută la identificarea clusterelor care consumă resurse în fereastra selectată.
4. Estimează timpul de rulare al clusterului
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Calculăm orele totale de rulare pentru fiecare cluster:
-
Utilizează timestamp-urile de creare și terminare
-
Gestionează clusterele care rulează în prezent (terminated_time lipsă)
-
Normalizează în ore
De ce este important: Această valoare este numitorul pentru utilizare — reprezentând timpul total de funcționare al clusterului în perioada selectată.
5. Obține rulările recente de joburi
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ În loc să preluăm întregul istoric de joburi (ceea ce este lent), \n Această funcție recuperează cele mairecente 10 rulări de joburi pentru diagnosticare rapidă.
În producție, puteți filtra după:
- job_id specific
- completed_only=true
- Fereastra de date (starttimefrom, starttimeto)
\
-
Calculează utilizarea și costul
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
Aceasta este inima logicii:
-
Parcurge fiecare cluster
-
Calculează timpul total de rulare al jobului pe cluster (utilizând API-ul de rulări de joburi)
-
Derivă procentul de utilizare = (jobhours / clusterrunning_hours) × 100
-
Estimează costul:
- Cost DBU bazat pe rată × DBU/hr
- Cost VM = nodecount × nodecost/hr × running_hours
De ce contează: \n Aceasta oferă o imagine unificată aeficienței și cheltuielilor — utilă pentru identificarea clusterelor cu cost ridicat dar utilizare redusă.
7. Orchestrează pipeline-ul
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Acest bloc final:
-
Recuperează datele
-
Efectuează calculul costurilor
-
Afișează DataFrame-ul sortat
În practică, acest DataFrame poate fi:
-
Exportat în Excel sau Delta Table
-
Trimis către dashboard-uri Power BI
-
Integrat în pipeline-uri de automatizare FinOps
\
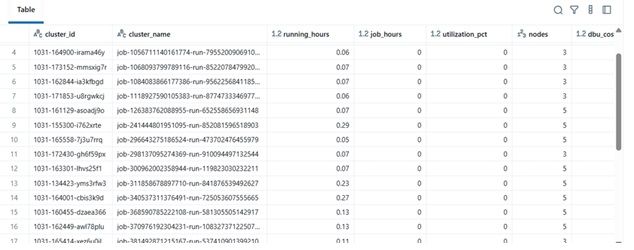
Exemplu de rezultate
| clustername | runninghours | jobhours | utilizationpct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36,5 | 28,0 | 76,7% | 4 | $142,8 | | dev-debug | 12,0 | 1,2 | 10,0% | 2 | $18,4 | | nightly-adf | 48,0 | 45,0 | 93,7% | 6 | $260,4 |
\ 
\ \
-
Beneficiul în lumea reală
Prin implementarea acestui analizor:
-
Echipele de inginerie pot urmări costul clusterului chiar și fără acces de audit.
-
Managerii obțin vizibilitate asupra clusterelor subutilizate.
-
DevOps poate termina automat clusterele cu utilizare redusă.
-
Finanțele pot valida facturile Databricks cu metrici interne.
În proiectul nostru MSC, am folosit aceasta ca parte a stack-ului de observabilitate a platformei de date — combinând datele din REST API, jurnalele de joburi ADF și tendințele de costuri într-un dashboard unificat.
\
Poate îți place și

Nasdaq și CME lansează noul Index Cripto Nasdaq-CME—O schimbare majoră în activele digitale

Casa Albă are planuri de rezervă pregătite în cazul în care instanța blochează tarifele lui Trump
